deleting twitter like a nerd
Written by

Intro
for a long time I’ve wanted to move on to the indieweb/fediverse world from twitter and co. I figured deleting my tweets would be a great waypoint for my transition1. Twitter didn’t provide any tools for batch deletion, and all the online twitter deletion services only allowed a limited number of deletions on their free tier2. So I decided to do some good old snooping and try to do it myself. It turned out to be much easier than I’d anticipated3.
Commencing Investigation
Open your browser’s network log panel (open devtools and find the network tab), you can see all the ongoing requests that your currently opened web page is making. If you delete a tweet, you’ll see a POST request is made to a DeleteTweet graphql endpoint.
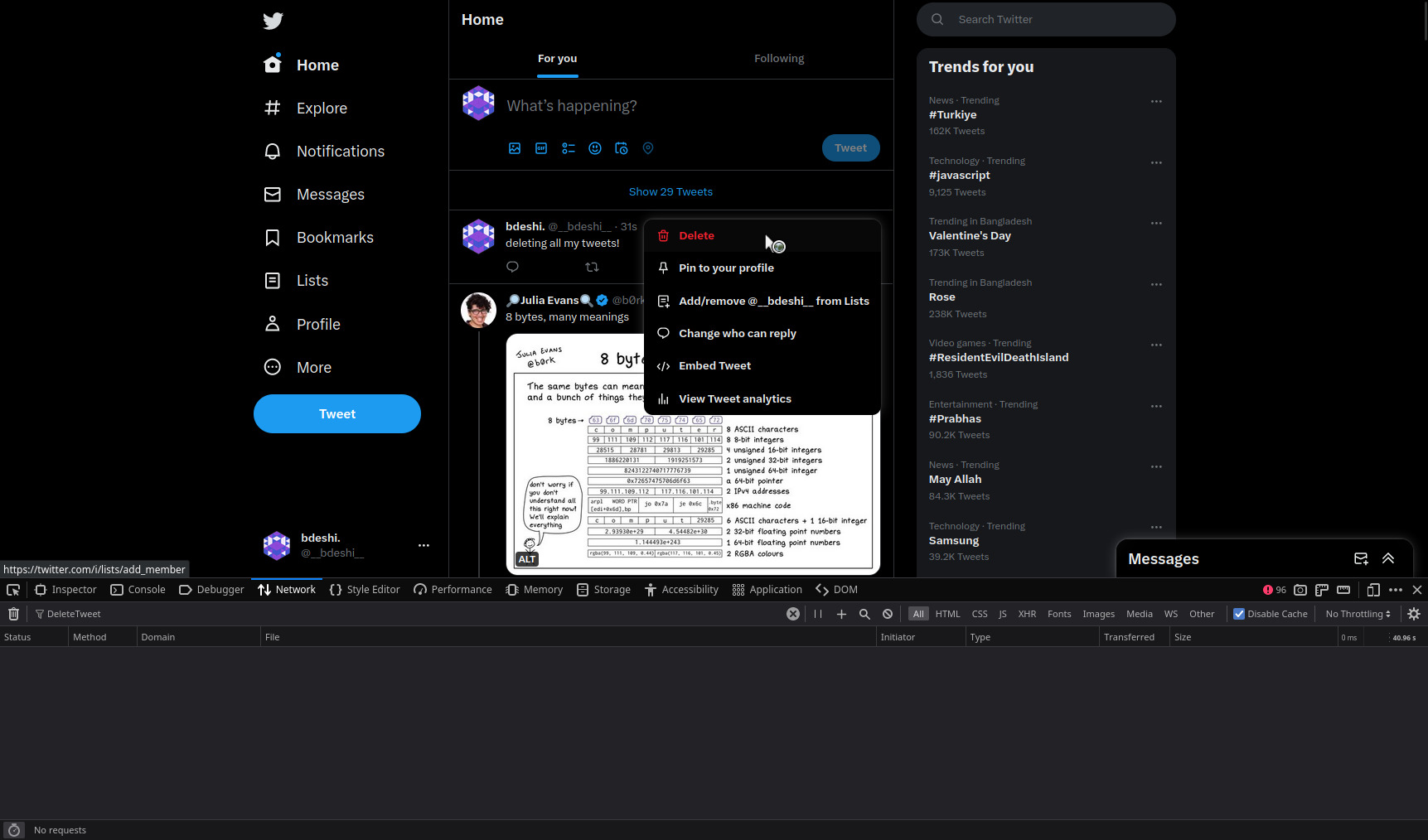
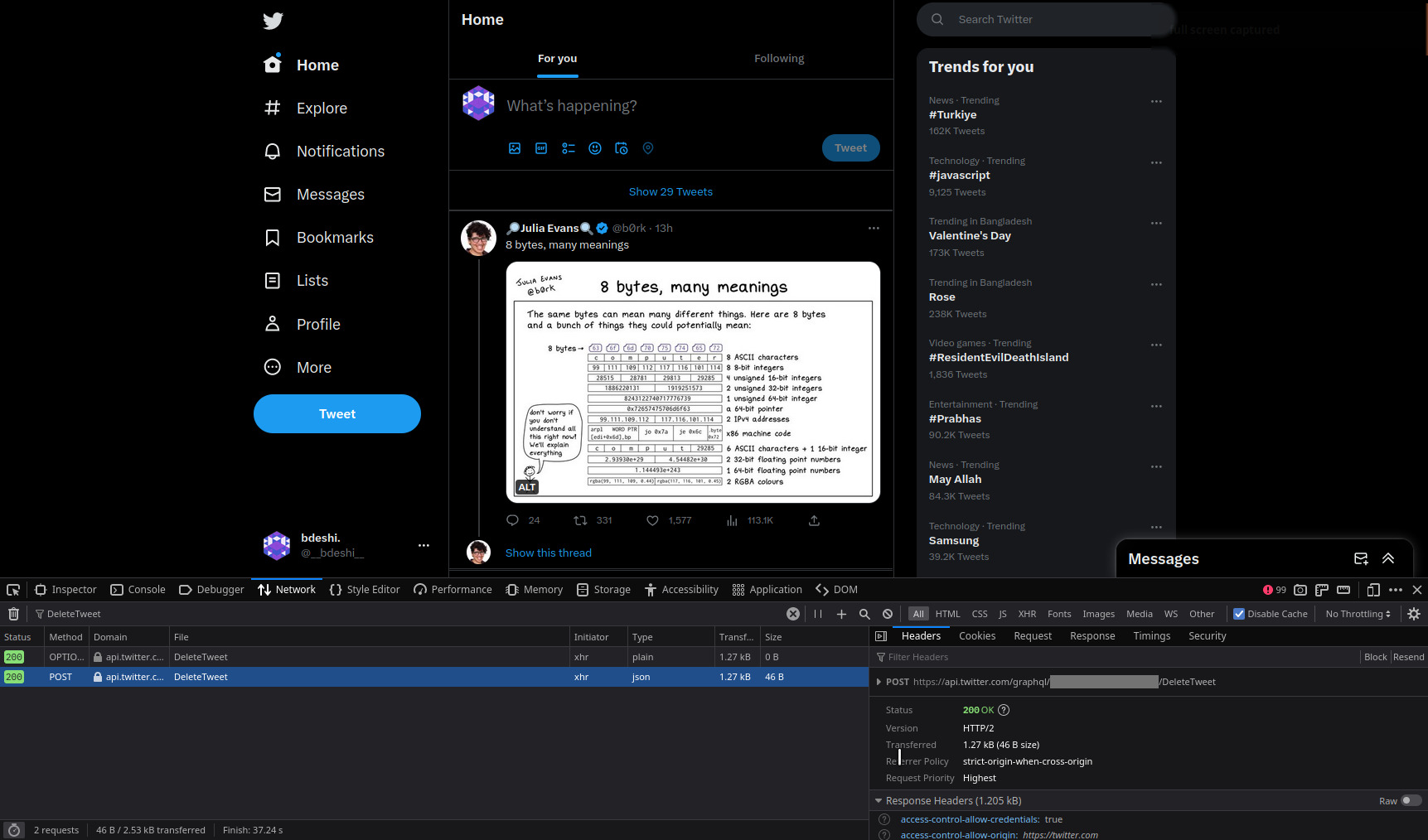
Let’s investigate this request. (I will be hiding values in subsequent images and snippets, which I thought might be sensitive.)
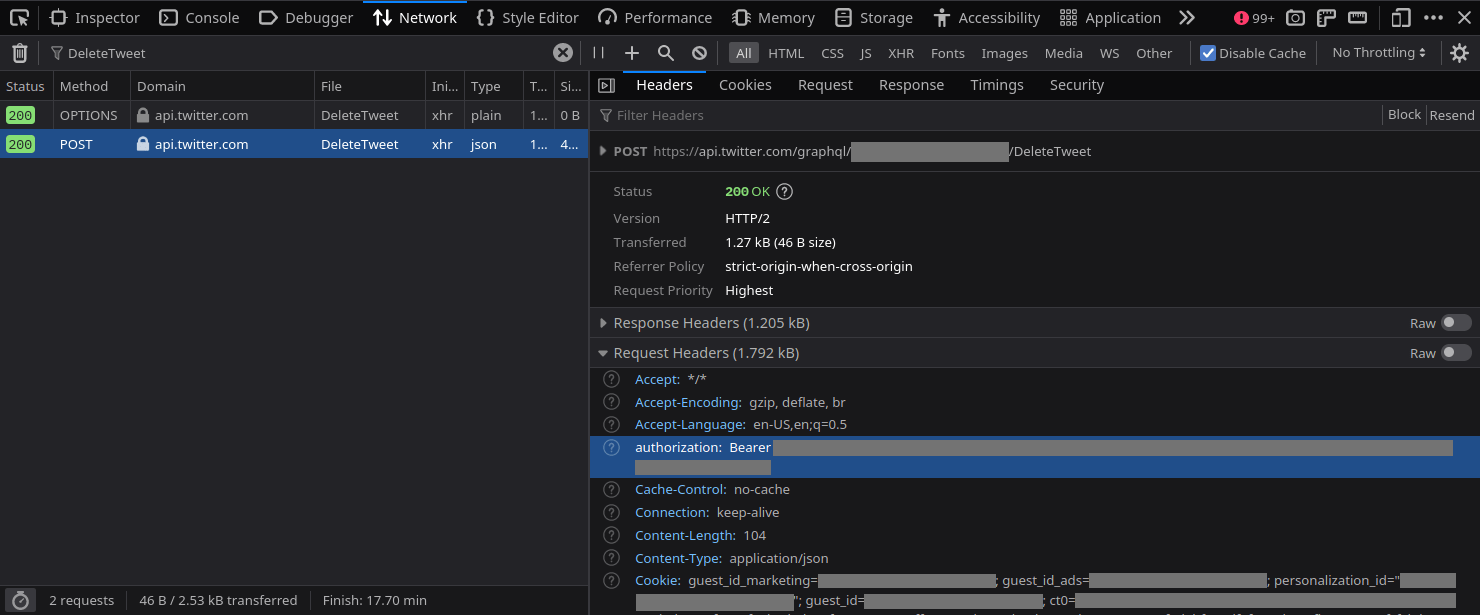
It looks like Twitter is creating an authentication token, probably from your login cookies. That’s actually helpful because we don’t have to worry about creating a token ourselves, we already got a header served on a plate.
Also, check the payload that is being sent in the request, and you’ll see a twitter_id being sent, which identifies which tweet to delete.
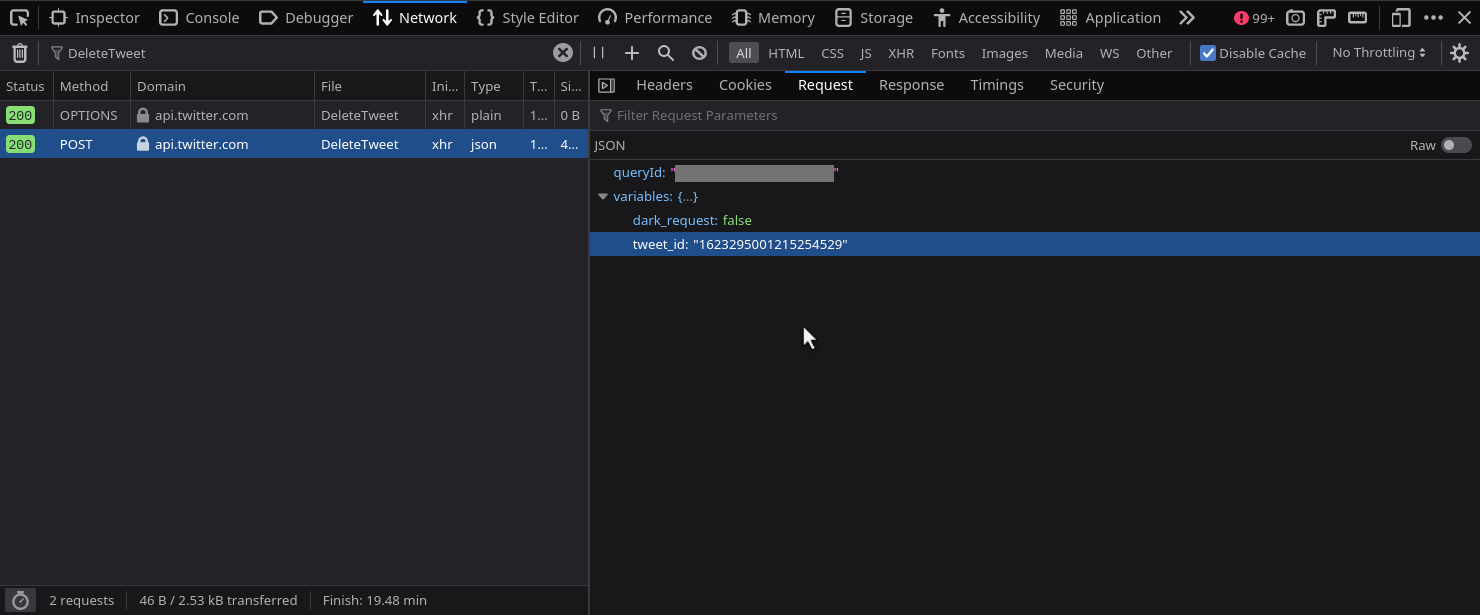
Okay, very informative stuff so far, right? You can find an interesting menu item in your browser’s developer tools, that allows you to copy a request as a self-contained curl command:
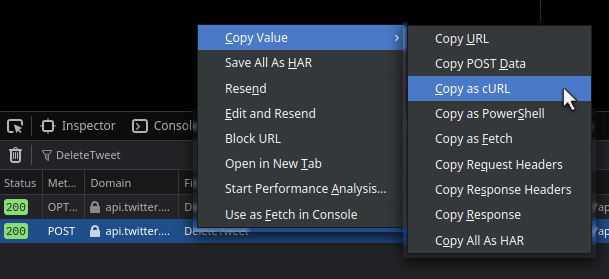
You will get a curl command like this, all headers already baked in for your happiness:
curl 'https://api.twitter.com/graphql/[REDACTED]/DeleteTweet'
-X POST
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/109.0'
-H 'Accept: */*'
-H 'Accept-Language: en-US,en;q=0.5'
-H 'Accept-Encoding: gzip, deflate, br'
-H 'Content-Type: application/json'
-H 'Referer: https://twitter.com/'
-H 'x-twitter-auth-type: OAuth2Session'
-H 'x-twitter-client-language: en'
-H 'x-twitter-active-user: yes'
-H 'x-csrf-token: [REDACTED]'
-H 'Origin: https://twitter.com'
-H 'Sec-Fetch-Dest: empty'
-H 'Sec-Fetch-Mode: cors'
-H 'Sec-Fetch-Site: same-site'
-H 'DNT: 1'
-H 'Sec-GPC: 1'
-H 'authorization: Bearer [REDACTED]'
-H 'Connection: keep-alive'
-H 'Cookie: [REDACTED]'
-H 'Pragma: no-cache'
-H 'Cache-Control: no-cache'
-H 'TE: trailers'
--data-raw '{"variables":{"tweet_id":"863987907815546881","dark_request":false},"queryId":"[REDACTED]"}'The request payload is sent with the --data-raw parameter.
You already know where this is going right? we can just run this curl command for every tweet we want to delete, and we are done! But how do you find the tweet_ids?
Collecting tweet IDs
Twitter will conveniently give you a list of all your tweet IDs (among a whole bunch of other things) if you request an archive of your twitter data.
Go to https://twitter.com/settings/download_your_data4. You will get a password verification prompt and after/if you pass this screen5, Twitter will start creating an archive of your data, and you should get a notification to download the archive within 24 hours, assuming Twitter is still working somewhat okay.
Download this archive, and extract the tweets.js file somewhere6. If you open this file, you will see a bunch of attributes for all your tweets as a gigantic list of javascript objects, among them will be an id field. For example:
window.YTD.tweets.part0 = [
{
"tweet" : {
"edit_info" : {
"initial" : {
"editTweetIds" : [
"774174446479290368"
],
"editableUntil" : "2016-09-09T09:45:46.163Z",
"editsRemaining" : "5",
"isEditEligible" : true
}
},
"retweeted" : false,
"source" : "<a href=\"http://twitter.com/download/android\" rel=\"nofollow\">Twitter for Android</a>",
"entities" : {
"hashtags" : [ ],
"symbols" : [ ],
"user_mentions" : [ ],
"urls" : [ ]
},
"display_text_range" : [
"0",
"138"
],
"favorite_count" : "0",
"id_str" : "774174446479290368",
"truncated" : false,
"retweet_count" : "0",
"id" : "774174446479290368",
"created_at" : "Fri Sep 09 09:15:46 +0000 2016",
"favorited" : false,
"full_text" : "A common joke evolved: there are 11 types of people, those who know binary, those who don't, and those who don't know what's 3 in binary 😄",
"lang" : "en"
}
},
/* more "tweet" object blocks */
]There will be a series of these tweet objects, one for each of your tweets.
Now you might think we can easily process these with jq, but look again at the first line: this file declares the data as a javascript object variable, which is not valid JSON and hence unreadable to jq.
cat tweets.js | jq -r '.[]'
# parse error: Invalid numeric literal at line 1, column 24Let’s do some command-line surgery on that first line7:
cat tweets.js | awk '{if (NR==1) print "["; else print $0}'This pipeline replaces the variable declaration in the first line with and array start token "[", which in turn makes this whole thing valid JSON.
[
{
"tweet" : {
/* ... */
}
},
/* ... */
] Anyway, now we can extract the IDs like so:
cat tweets.js | awk '{if (NR==1) print "["; else print $0}' | jq -r '.[] | .tweet.id'which returns a nice list of IDs:
825335392257843201
825194054178664448
823385342837305345
...All Together Now
Now lets combine all these parts together into a looping shell script. Copy the curl command for /DeleteTweet from your browser’s network panel, then run it in loop over the tweet IDs from jq:
for TWEET_ID in $(cat tweets.js | awk '{if (NR==1) print "["; else print $0}' | jq -r '.[] | .tweet.id'); do
curl -s 'https://api.twitter.com/graphql/[REDACTED]/DeleteTweet' -X POST
# ... hidden for brevity
-H 'Accept-Encoding: identity'
# ... hidden for brevity
--data-raw '{"variables":{"tweet_id":"' $TWEET_ID '","dark_request":false},"queryId":"[REDACTED]"}';
echo '';
done;Note that I made some changes:
- inserted
$TWEET_IDinto the--data-rawparameter - modified the
Accept-EncodingHeader value toidentityso that responses are uncompressed plain text8 - added the
-sswitch to curl to hide request progress - added an empty
echo ''command to separate each curl output by a new line.
After running this loop, you should start seeing outputs like this:
{"data":{"delete_tweet":{"tweet_results":{}}}}
{"data":{"delete_tweet":{"tweet_results":{}}}}
{"data":{"delete_tweet":{"tweet_results":{}}}}
{"data":{"delete_tweet":{"tweet_results":{}}}}
...Let it keep running, and refresh your twitter profile page to see your tweet count going down to!
Some notes
All this might seem very complicated, but writing this blog post took much longer than this entire investigation and execution process, and definitely much faster than using Twitter’s APIs as intended (are Twitter APIs paid yet?), without having to pay anybody anything. At least until Twitter reads my post (unlikely) and puts roadblocks.
Although there may be some edge cases. For example, the tweets.js file calls the tweet object window.YTD.tweets.part0 which hints that they might segment tweets into separate variables or files if the tweet count crosses some limits; authentication tokens might need to be refreshed periodically, etc.
Curiously, after going through this process, my twitter timeline became empty, but the headline is still showing I have 8 tweets. What kind of limbo are these 8 tweets going through?
This article was motivated by The Penguins Club BlogTalk event. #blogtalk #penguinsclub
- I didn’t want to deactivate my entire twitter account outright, because there are some interesting feeds I follow, and also I’m planning to view my twitter feed in a federated service, somehow↩
- yes, deleting tweets is such a high-demand task now that there are multiple paid-for services for this↩
- feels like the phrase “You won’t believe” should be here somewhere…↩
- or if you want to get there manually, Twitter settings > account > Download an archive of your data↩
- Twitter sends a one-time authentication code to your email or phone that is valid for 10 minutes. But in my recent experience, sometimes this code took longer than 10 minutes to be delivered, so I had to retry a few times. I remember someone famous said he’s making Twitter faster.↩
- you might like to take a break and browse the archive to revel in the amount of data you have amassed on Twitter.↩
- or you can also choose the less pretentious route, and edit the file in a text editor↩
- or you can keep this header as-is and pipe curl’s output to gunzip:
curl -s ... --data-raw '...' | gunzip -q↩
Join the discussion